De essentie van indexatievalidatie met server logs
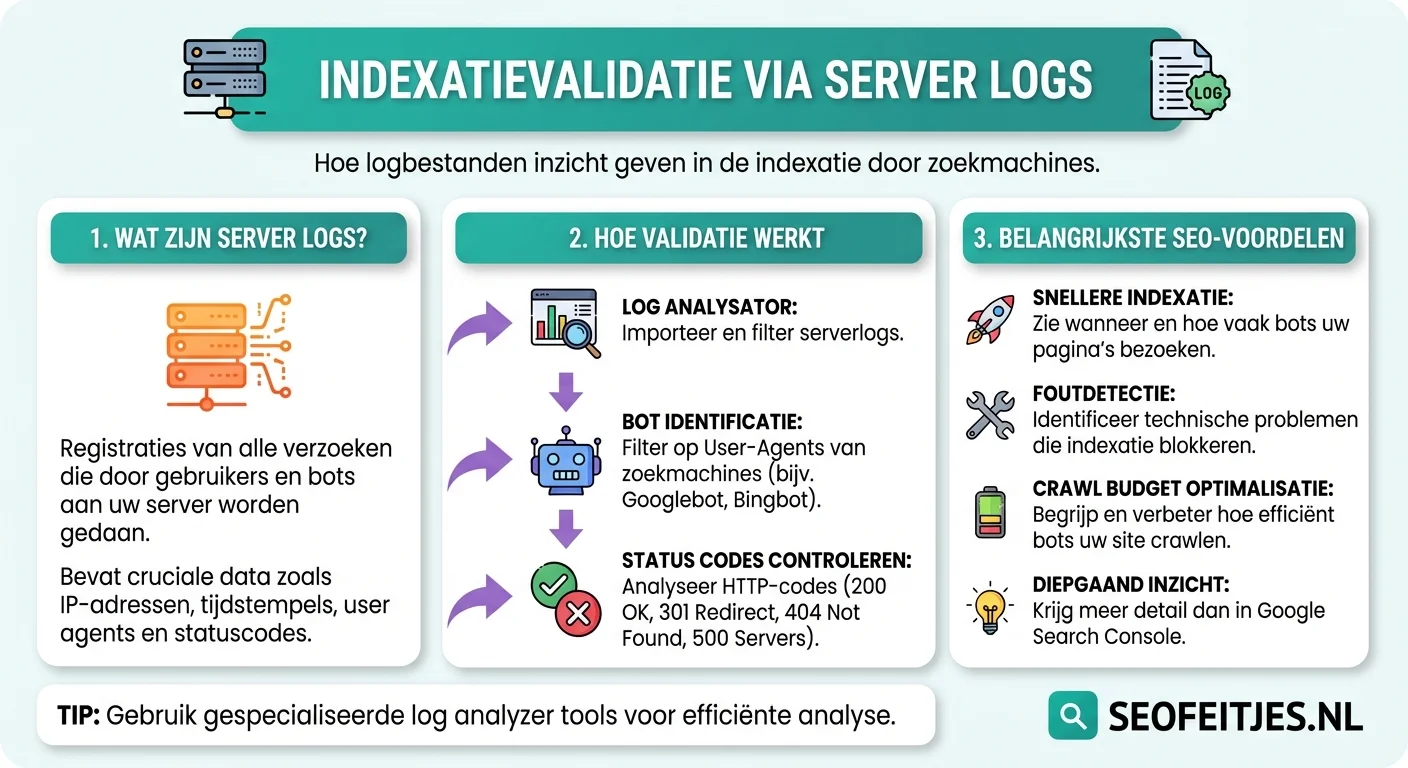
Server logs vormen een onmisbare bron van informatie voor SEO-professionals die willen begrijpen hoe zoekmachines hun website benaderen. Deze logbestanden bevatten gedetailleerde informatie over elk verzoek dat naar de webserver wordt gestuurd, inclusief het tijdstip, de opgevraagde URL, de HTTP-statuscode en de identificatie van de bezoeker. Bovendien geven ze cruciale inzichten in het gedrag van zoekmachinebots zoals Googlebot, waardoor je kunt valideren of je content effectief wordt gecrawld en geïndexeerd.
Het belang van deze validatie wordt nog duidelijker wanneer we kijken naar volgens Google het principe van crawlbudget-optimalisatie. Zoekmachines hebben namelijk beperkte middelen om websites te crawlen, en zonder inzicht in hun gedrag kun je kostbare crawlcapaciteit verspillen aan onbelangrijke pagina's. Daarnaast helpt een grondige analyse van server logs bij het identificeren van technische problemen die de indexatie kunnen belemmeren, zoals trage laadtijden of foutcodes.
Voor een effectieve Googlebot crawlgedrag en crawlfrequentie analyseren is het essentieel om de juiste metrics uit je logs te halen. Deze gegevens onthullen bijvoorbeeld welke delen van je site frequent worden bezocht door zoekmachinebots en welke gebieden mogelijk worden verwaarloosd. Bovendien kun je hiermee controleren of belangrijke nieuwe content snel wordt opgepikt en of er geen technische barrières zijn die de indexatie vertragen.
Het proces van log-analyse voor indexatievalidatie
Het analyseren van server logs begint met het verzamelen van de juiste data. De meeste webservers, of het nu Apache, Nginx of IIS betreft, genereren automatisch uitgebreide logbestanden. Deze logs bevatten echter veel meer informatie dan alleen crawlgedrag van zoekmachines, daarom is filtering een cruciale eerste stap. Je moet bijvoorbeeld specifiek zoeken naar verzoeken van bekende bot user agents en deze valideren tegen officiële IP-ranges om nepbots uit te sluiten.
Voor een grondige analyse is het belangrijk om verschillende metrics in samenhang te bekijken. Dit betekent dat je niet alleen kijkt naar welke URLs worden bezocht, maar ook naar de frequentie, de ontvangen HTTP-statuscodes en de tijd tussen opeenvolgende bezoeken. Terwijl je deze gegevens verzamelt, is het essentieel om ze te koppelen aan je crawlbudget optimalisatie strategieën, zodat je kunt bepalen of je crawlbudget efficiënt wordt besteed.
Het interpreteren van de verzamelde data vereist expertise en context. Bijvoorbeeld, een hoge crawlfrequentie op bepaalde URLs kan zowel positief als negatief zijn, afhankelijk van het type content en je SEO-doelstellingen. Daarom is het cruciaal om de logdata te combineren met andere bronnen zoals Google Search Console en je eigen content-strategie om een volledig beeld te krijgen.
Technische aspecten van indexatievalidatie
Bij het technische aspect van indexatievalidatie spelen verschillende factoren een rol. Ten eerste moet je zorgen dat je logging correct is geconfigureerd om alle relevante informatie vast te leggen. Dit betekent dat je minimaal het tijdstip, de URL, de statuscode, de user agent en het IP-adres moet registreren. Daarnaast is het waardevol om ook de laadtijd en de grootte van de response mee te nemen, omdat deze factoren invloed hebben op de crawl-efficiëntie.
Een belangrijk onderdeel van de technische implementatie is de robots.txt optimalisatie op basis van crawldata, waarbij je gebruikt maakt van de inzichten uit je loganalyse. Hierbij kijk je bijvoorbeeld naar pagina's die veel crawlcapaciteit verbruiken maar weinig waarde toevoegen aan je site. Vervolgens kun je deze URLs strategisch blokkeren of het crawlen ervan beperken om je crawlbudget effectiever in te zetten.
Het is essentieel om je analyse-setup regelmatig te valideren en bij te werken. Zoekmachines evoluren constant en kunnen hun crawlgedrag aanpassen, waardoor je monitoring moet meebewegen. Bovendien moet je rekening houden met verschillende bot-types, waaronder mobiele crawlers en specifieke bots voor bijvoorbeeld afbeeldingen of JavaScript-rendering.
Praktische implementatie en monitoring
De praktische implementatie van indexatievalidatie begint met het opzetten van een gestructureerd proces. Dit betekent dat je niet alleen incidenteel logs analyseert, maar een continue monitoring implementeert. Hiervoor kun je gebruik maken van gespecialiseerde tools zoals Screaming Frog Log Analyzer, of meer geavanceerde platforms zoals Botify of OnCrawl die realtime monitoring mogelijk maken.
In de dagelijkse praktijk is het belangrijk om alerts in te stellen voor ongewone patronen. Dit kunnen bijvoorbeeld plotselinge veranderingen in crawlfrequentie zijn, een toename in bepaalde foutcodes, of het verschijnen van nieuwe bot-types in je logs. Door deze signalen vroeg op te pikken, kun je snel reageren op potentiële problemen voordat ze impact hebben op je rankings.
Het is cruciaal om je bevindingen te documenteren en trends over tijd bij te houden. Dit helpt niet alleen bij het identificeren van langetermijnpatronen, maar ondersteunt ook bij het maken van datagedreven beslissingen over technische SEO-aanpassingen. Bovendien kun je hiermee de effectiviteit van je optimalisaties meten en waar nodig bijsturen.
Geavanceerde analysetechnieken
Voor diepgaande inzichten is het waardevol om geavanceerde analysetechnieken toe te passen op je logdata. Een belangrijke techniek is het segmenteren van URLs op basis van content-type, template of sectie van je website. Hierdoor kun je bijvoorbeeld zien of bepaalde delen van je site ondermaats worden gecrawld of juist te veel crawlcapaciteit verbruiken.
Machine learning-algoritmes kunnen helpen bij het identificeren van patronen die met het blote oog moeilijk te herkennen zijn. Deze tools kunnen bijvoorbeeld voorspellen wanneer Googlebot bepaalde secties van je site zal bezoeken, of anomalieën detecteren in crawlpatronen die menselijke analisten mogelijk zouden missen. Daarnaast helpen ze bij het automatisch categoriseren van crawlgedrag en het genereren van voorspellende inzichten.
Het combineren van logdata met andere databronnen levert vaak waardevolle nieuwe inzichten op. Door bijvoorbeeld server logs te koppelen aan conversiedata, kun je bepalen of pagina's die veel organisch verkeer genereren ook voldoende crawlaandacht krijgen. Ook het matchen van crawldata met interne linkstructuur kan helpen bij het optimaliseren van de verdeling van linkwaarde en crawlbudget.
Conclusie en toekomstperspectief
Indexatievalidatie via server logs blijft een fundamenteel onderdeel van technische SEO, maar de technieken en tools evolueren continu. Met de opkomst van nieuwe crawlers, zoals die van AI-systemen, wordt het steeds belangrijker om je monitoring aan te passen en uit te breiden. Bovendien maken verbeterde analysetools het mogelijk om steeds gedetailleerdere inzichten te verkrijgen uit je logdata.
De toekomst van indexatievalidatie ligt in het verder automatiseren en verfijnen van analyses. Machine learning zal een steeds grotere rol spelen bij het identificeren van patronen en het voorspellen van crawlgedrag. Daarnaast zal de integratie met andere SEO-tools en -data steeds naadlozer worden, waardoor je nog beter geïnformeerde beslissingen kunt nemen over je technische SEO-strategie.
Het blijft essentieel om je kennis en tooling up-to-date te houden, aangezien zoekmachines hun crawl- en indexatieprocessen blijven ontwikkelen. Door proactief te monitoren en te optimaliseren, zorg je ervoor dat je website optimaal wordt gecrawld en geïndexeerd, wat uiteindelijk leidt tot betere zoekresultaten en meer organisch verkeer.